
Effective disaster recovery planning is paramount for any organization, ensuring business continuity in the face of unforeseen events. From natural disasters to cyberattacks, the potential for disruption is ever-present. A well-structured plan mitigates risks, minimizes downtime, and safeguards valuable data, ultimately protecting your reputation and bottom line. This guide explores the key elements of creating and implementing a robust disaster recovery strategy.
We will delve into crucial aspects such as risk assessment, recovery strategies (hot, cold, and warm sites), data backup and recovery methods, and the importance of rigorous testing and communication protocols. By understanding these components, you can build a resilient framework capable of weathering any storm.
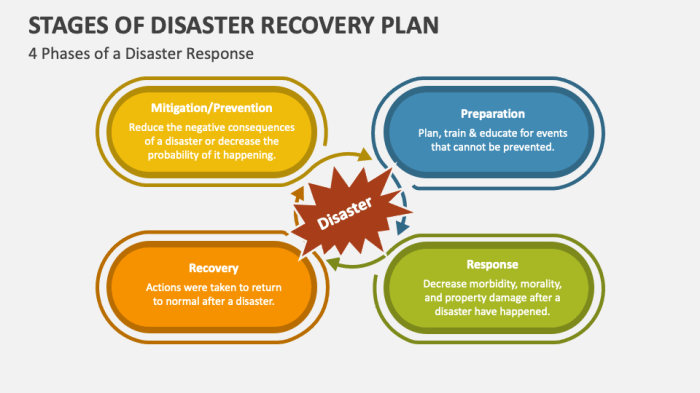
Defining Disaster Recovery Planning

Disaster recovery planning (DRP) is the process of creating a detailed strategy to ensure business continuity in the face of unforeseen events. A robust DRP Artikels the steps an organization will take to restore its critical systems and data after a disaster, minimizing downtime and data loss. It’s a proactive approach to managing risk, shifting the focus from reacting to an emergency to preparing for it.
Core Components of a Comprehensive Disaster Recovery Plan
A comprehensive DRP comprises several key components working in concert. These include a detailed risk assessment identifying potential threats, a business impact analysis pinpointing critical systems and data, a recovery strategy outlining how to restore systems and data, a communication plan ensuring clear and timely information flow during and after a disaster, and a testing and maintenance plan to ensure the DRP remains effective. Each component is crucial for a successful recovery. A well-defined recovery time objective (RTO) and recovery point objective (RPO) are also essential, setting targets for system restoration and data recovery. The plan also needs to detail the roles and responsibilities of individuals and teams involved in the recovery process.
Disaster Recovery versus Business Continuity Planning
While often used interchangeably, disaster recovery and business continuity planning (BCP) are distinct yet complementary concepts. Disaster recovery focuses specifically on restoring IT systems and data after a disruption. Business continuity planning, on the other hand, encompasses a broader scope, addressing the overall continuation of business operations, including non-IT aspects like supply chain management and human resources. A BCP may incorporate a DRP as one of its components, but it extends beyond purely technological recovery. In essence, DRP is a subset of BCP.
Examples of Disasters Requiring Planning
A wide range of events necessitate disaster recovery planning. These include natural disasters like earthquakes, floods, hurricanes, and wildfires; technological failures such as hardware malfunctions, software bugs, and cyberattacks; human errors such as accidental data deletion or system misconfiguration; and external factors like power outages, terrorist attacks, and pandemics. Each disaster type demands a tailored approach within the overall DRP framework.
Comparison of Proactive and Reactive Disaster Recovery Strategies
| Strategy | Advantages | Disadvantages | Example Scenarios |
|---|---|---|---|
| Proactive | Reduced downtime, minimized data loss, improved business resilience, cost-effective in the long run | Requires upfront investment in planning and infrastructure, ongoing maintenance, potential for unused resources | Regular system backups, offsite data storage, disaster drills, failover systems implementation |
| Reactive | Lower initial investment, potentially faster response to unexpected events | Significant downtime, substantial data loss, high recovery costs, potential business disruption, reputational damage | Rushing to find backup tapes after a ransomware attack, scrambling to rebuild systems after a fire, relying on ad-hoc solutions during a natural disaster |
Risk Assessment and Business Impact Analysis

Effective disaster recovery planning hinges on a comprehensive understanding of potential risks and their impact on business operations. A robust risk assessment and business impact analysis (BIA) are crucial first steps, providing the foundation for developing a tailored and effective recovery strategy. This process involves identifying critical business functions, analyzing their vulnerabilities, and quantifying the potential consequences of disruptions.
Understanding the interconnectedness of various business functions is paramount. A thorough BIA helps organizations visualize how disruptions to one area can cascade and impact others. For example, a power outage might initially affect server operations, but this could then lead to website downtime, halting online sales and impacting customer service. The analysis quantifies these impacts, allowing for prioritized resource allocation during recovery.
Identifying Key Business Functions and Their Dependencies
This involves systematically cataloging all critical business functions. This could include sales, production, customer service, IT infrastructure, and finance. For each function, the analysis identifies its dependencies – what other functions, systems, or resources it relies on. A dependency matrix, a table showing the relationships between functions and their dependencies, is a useful tool here. For instance, the sales function depends on the IT infrastructure for order processing and the customer service function relies on the sales function for information. Understanding these dependencies helps anticipate the ripple effects of a disruption.
Methods for Quantifying the Impact of Potential Disruptions
Quantifying the impact of disruptions is crucial for prioritizing recovery efforts. Several methods exist. One common approach is to assign a monetary value to the potential loss resulting from a disruption. This could include lost revenue, fines for non-compliance, or costs associated with recovery efforts. Another method is to assign a qualitative impact rating, such as low, medium, or high, based on factors like the severity and duration of the disruption and its impact on the organization’s reputation. For example, a short-term power outage affecting a small part of the operation might be rated as low impact, whereas a prolonged outage affecting critical systems could be rated as high.
Techniques for Conducting a Thorough Risk Assessment
A thorough risk assessment involves identifying potential threats, vulnerabilities, and their likelihood of occurrence. Techniques include brainstorming sessions, interviews with key personnel, and analysis of historical data. Vulnerability assessments of IT systems and physical security audits are also important. Each identified risk should be analyzed considering its likelihood and potential impact. This often involves using a risk matrix, a visual tool that plots likelihood against impact to prioritize risks. For example, a high-likelihood, high-impact risk (such as a major natural disaster in a high-risk area) demands immediate attention and mitigation strategies, unlike a low-likelihood, low-impact risk (such as a minor software glitch).
Business Impact Analysis Process Flowchart
The flowchart would depict a sequential process. It would start with identifying critical business functions and their dependencies. This would be followed by assessing potential disruptions and their likelihood. Next, the impact of each disruption on each function would be analyzed and quantified (monetarily or qualitatively). Finally, the flowchart would show the prioritization of recovery efforts based on the quantified impact and the development of recovery strategies. The flowchart could visually represent this sequential process using various shapes to represent different stages, with arrows indicating the flow of the analysis. The final output would be a prioritized list of recovery strategies, aligned with the business’s risk tolerance and recovery objectives.
Recovery Strategies and Objectives
Effective disaster recovery hinges on well-defined recovery strategies and objectives. These strategies dictate how quickly and completely an organization can resume operations after a disruptive event. Clearly defined objectives provide measurable targets for the recovery process, ensuring that business continuity is maintained to an acceptable level.
Choosing the right recovery strategy is crucial for minimizing downtime and data loss. The selection process depends heavily on factors such as the organization’s size, the criticality of its systems, and its budget. Establishing realistic Recovery Time Objectives (RTOs) and Recovery Point Objectives (RPOs) helps to guide this selection and measure the success of the recovery plan.
Recovery Strategies: Hot, Warm, and Cold Sites
Different recovery strategies offer varying levels of speed and cost. A hot site, warm site, and cold site represent points along a spectrum of readiness and expense.
- Hot Site: A fully operational replica of the primary data center. It’s ready to take over immediately with minimal downtime. This offers the fastest recovery but is the most expensive option, requiring ongoing maintenance and replication of all data and systems. Imagine a mirror image of your main office, fully staffed and ready to go at a moment’s notice.
- Warm Site: A site with essential infrastructure (power, network, etc.) in place but lacking fully replicated data. It requires some time for data restoration and system configuration before becoming fully operational. This offers a balance between cost and recovery time, perhaps taking a few hours to become fully functional. Think of it as a partially furnished office—you have the space and utilities, but you still need to bring in some furniture and equipment.
- Cold Site: A basic facility with only essential utilities (power, network). It requires significant setup time to install and configure hardware and software, and restore data. This is the least expensive option, but recovery time is significantly longer, potentially days or even weeks. This is akin to an empty office space – you have the shell, but everything else needs to be brought in and set up from scratch.
Establishing Recovery Time Objectives (RTO) and Recovery Point Objectives (RPO)
RTO and RPO are critical metrics in disaster recovery planning. They define acceptable levels of downtime and data loss.
- Recovery Time Objective (RTO): The maximum tolerable downtime after a disaster before critical business functions are impacted. For example, an RTO of 4 hours means that critical systems must be restored within four hours of a disaster. A lower RTO indicates a higher priority for quick recovery.
- Recovery Point Objective (RPO): The maximum acceptable data loss measured in time. An RPO of 24 hours means that a maximum of 24 hours of data can be lost during a disaster. A lower RPO signifies a higher priority for data protection and minimizing data loss. Consider a financial institution; their RPO would likely be far lower than a small blog.
The process of establishing RTOs and RPOs involves analyzing business processes, identifying critical systems, and determining the impact of downtime and data loss. This analysis often incorporates discussions with business stakeholders to establish priorities and acceptable levels of risk. For instance, a hospital’s RTO and RPO for patient records would be significantly lower than those for a less critical system like email.
Factors to Consider When Selecting a Recovery Strategy
Several factors influence the choice of recovery strategy. A careful evaluation of these aspects ensures that the chosen strategy aligns with the organization’s specific needs and resources.
- Cost: Hot sites are the most expensive, followed by warm sites, and then cold sites.
- Recovery Time: Hot sites offer the fastest recovery, while cold sites take the longest.
- Data Loss: Hot sites minimize data loss, while cold sites may result in substantial data loss.
- Criticality of Systems: The importance of business systems influences the urgency of recovery and thus the choice of strategy.
- Budget: Available resources dictate the feasibility of different options.
- Regulatory Compliance: Industry regulations may mandate specific recovery timeframes and data protection measures.
Data Backup and Recovery
Data backup and recovery is a critical component of any robust disaster recovery plan. The ability to quickly and efficiently restore data after a disruptive event is paramount to minimizing business downtime and ensuring operational continuity. This section details various backup methods, storage solutions, testing best practices, and a practical example of data restoration.
Data Backup Methods
Choosing the right data backup method depends on factors such as recovery time objectives (RTOs), recovery point objectives (RPOs), storage capacity, and budget. Different methods offer varying levels of speed, efficiency, and storage requirements.
- Full Backup: This method copies all data from the source to the backup storage. It’s the most comprehensive but also the slowest and most storage-intensive. Full backups serve as the foundation for other backup methods and are typically performed less frequently.
- Incremental Backup: This method only backs up data that has changed since the last full or incremental backup. It’s faster and more storage-efficient than full backups but requires a full backup as a starting point. Recovery involves restoring the last full backup and then sequentially applying all subsequent incremental backups.
- Differential Backup: This method backs up data that has changed since the last full backup. It’s faster than full backups and more storage-efficient than incremental backups, but restoring data requires the last full backup and the most recent differential backup.
Data Storage Solutions for Disaster Recovery
The choice of storage solution impacts the accessibility, security, and cost-effectiveness of your disaster recovery strategy.
- On-site storage (Tape, Disk): Provides quick access but is vulnerable to the same disasters affecting the primary site. Tape offers high storage density and cost-effectiveness but slower retrieval times. Disk offers faster access but is typically more expensive per unit of storage.
- Off-site storage (Cloud, Tape Vault): Offers better protection against site-specific disasters. Cloud storage provides scalability and accessibility, while tape vaults offer a cost-effective, secure, and offline storage option.
- Replicated Storage (SAN, NAS): Data is replicated to a secondary location, providing high availability and quick recovery times. Storage Area Networks (SANs) offer high performance and scalability, while Network Attached Storage (NAS) devices are simpler to manage but may offer lower performance.
Data Backup and Recovery Testing Best Practices
Regular testing is crucial to ensure the effectiveness of your backup and recovery procedures. Testing should simulate real-world scenarios to identify and address potential issues before a disaster occurs.
- Regular Testing Schedule: Establish a regular schedule for testing backups, including full restorations and partial restorations. The frequency should align with the criticality of the data and the RPOs.
- Test Different Scenarios: Simulate various disaster scenarios, such as hardware failure, software corruption, and natural disasters. This will help identify vulnerabilities and refine your recovery procedures.
- Document the Process: Maintain detailed documentation of the testing process, including the steps taken, the results obtained, and any issues encountered. This documentation will be invaluable during a real disaster.
- Involve Relevant Personnel: Involve IT staff and other key personnel in the testing process to ensure everyone understands their roles and responsibilities during a recovery operation.
Restoring Data from Backups: Example Scenario
Imagine a scenario where a server hosting critical customer databases crashes due to a hardware failure. The company utilizes a full backup strategy performed weekly, supplemented by daily incremental backups. The last full backup was taken on Monday, and the failure occurred on Friday.
To restore the data, the IT team would first restore the full backup from Monday. Then, they would sequentially apply the incremental backups from Tuesday, Wednesday, and Thursday. This process ensures that all data changes made since the last full backup are incorporated, minimizing data loss to a maximum of one day. The restored database would then be tested thoroughly to ensure data integrity before being brought back online.
Disaster Recovery Testing and Exercises

A robust disaster recovery plan is only as good as its execution. Thorough testing is crucial to identify weaknesses and ensure the plan’s effectiveness in a real-world crisis. Regular testing allows for iterative improvements, enhancing the organization’s resilience and minimizing potential downtime and data loss.
Regular testing and updates are paramount to maintaining a viable disaster recovery plan. Without these, the plan becomes outdated and ineffective, potentially leading to significant disruptions during a real disaster. Changes in technology, personnel, or business processes necessitate periodic review and adjustments to the plan. Furthermore, testing reveals unforeseen challenges and allows for the refinement of procedures, ultimately improving the organization’s response capabilities.
Disaster Recovery Testing Methods
Several methods exist for testing a disaster recovery plan, each offering a different level of intensity and resource commitment. These methods range from low-cost, low-impact exercises to full-scale simulations that mirror a real disaster scenario. The choice of method depends on the organization’s size, complexity, risk tolerance, and available resources.
Tabletop Exercises
Tabletop exercises are low-cost, low-impact simulations that involve key personnel gathering to discuss the plan’s response to various hypothetical disaster scenarios. Participants walk through the plan step-by-step, identifying potential bottlenecks, communication breakdowns, and other weaknesses. This collaborative approach fosters team cohesion and improves understanding of individual roles and responsibilities. While not a full-scale test of the technical infrastructure, tabletop exercises provide valuable insights into the plan’s procedural aspects and can be conducted frequently with minimal disruption.
Full-Scale Tests
Full-scale tests involve the actual activation of the disaster recovery plan and the utilization of backup systems and infrastructure. These tests are more resource-intensive and disruptive but provide the most comprehensive evaluation of the plan’s effectiveness. They test the entire recovery process, from initiating the plan to restoring critical systems and data. The insights gained from a full-scale test are invaluable, but the cost and disruption associated with such tests necessitate careful planning and scheduling. A full-scale test might involve relocating to a secondary data center or utilizing cloud-based resources to simulate a complete system failure.
Checklist for Conducting a Successful Disaster Recovery Drill
Prior to conducting any disaster recovery drill, a comprehensive checklist ensures a smooth and effective exercise. This checklist should include tasks such as: defining clear objectives, identifying participants and their roles, preparing the necessary resources (data, systems, documentation), establishing communication protocols, developing a detailed scenario, documenting the exercise, and conducting a post-exercise review to identify areas for improvement. A well-structured checklist minimizes the risk of overlooking critical steps and ensures the drill’s success.
Comparison of Tabletop Exercise and Full-Scale Test
| Tabletop Exercise | Full-Scale Test |
|---|---|
| Participants gather to discuss plan responses to hypothetical scenarios. | Actual activation of the disaster recovery plan and utilization of backup systems. |
| Low cost, low impact, focuses on procedural aspects. | High cost, high impact, tests the entire recovery process. |
| Identifies procedural weaknesses and communication breakdowns. | Tests the technical infrastructure and data recovery capabilities. |
| Can be conducted frequently with minimal disruption. | Requires careful planning and scheduling due to disruption. |
| Suitable for regular testing and refinement of the plan. | Provides comprehensive evaluation of the plan’s effectiveness. |
Communication and Coordination

Effective communication and coordination are the cornerstones of a successful disaster recovery plan. Without a robust communication strategy, even the most meticulously crafted recovery plan can falter, leading to prolonged downtime, increased financial losses, and reputational damage. A well-defined communication plan ensures that all stakeholders are informed, coordinated, and working towards a common goal during a crisis.
Establishing clear communication channels during a disaster is paramount. The ability to quickly and effectively disseminate information to the right people at the right time is crucial for minimizing disruption and accelerating the recovery process. This involves identifying key personnel, defining communication protocols, and selecting appropriate communication tools. Failure to do so can lead to confusion, misinformation, and delays in critical decision-making.
Roles and Responsibilities of Key Personnel
A clearly defined roles and responsibilities matrix for key personnel is essential. This matrix should Artikel the specific tasks and responsibilities of each individual or team during a disaster recovery event. For example, a designated communication lead would be responsible for disseminating information, a technical lead would manage the restoration of IT systems, and a business continuity lead would oversee the overall recovery process. This ensures accountability and prevents duplication of effort. Each role should include contact information, alternate contacts, and escalation paths for critical situations.
Effective Communication Strategies for Stakeholders
Effective communication strategies must cater to diverse stakeholder needs. This involves utilizing a multi-channel approach, incorporating various communication methods to ensure message delivery. For example, a combination of email, SMS, phone calls, and potentially even social media updates might be necessary to reach all stakeholders. Consider the urgency and importance of the information when selecting the communication method. For critical updates, immediate methods such as phone calls or SMS messages are preferred. Regular updates, even if no significant changes have occurred, are crucial to maintain stakeholder confidence and reduce anxiety. Transparency and honesty are vital in maintaining trust during a stressful situation.
Communication Plan: Notification Procedures and Escalation Paths
A comprehensive communication plan should Artikel detailed notification procedures and escalation paths. This plan should specify who needs to be notified, the order of notification, the methods of notification, and the content of the messages. It should also detail escalation paths, identifying the individuals or teams responsible for handling escalating issues.
For instance, a tiered notification system might be implemented. Tier 1 notifications could involve immediate alerts to critical personnel using SMS and phone calls, informing them of the disaster and their initial responsibilities. Tier 2 notifications could be broader email communications providing more detailed information to a wider range of stakeholders. Tier 3 notifications could involve public statements or press releases, depending on the nature and scale of the disaster. Each notification should clearly state the situation, the actions being taken, and the expected timeline for recovery. Regular status updates should follow to keep stakeholders informed of progress. The plan should also include procedures for managing media inquiries and addressing public concerns.
Post-Disaster Recovery and Lessons Learned
Successful disaster recovery isn’t just about restoring systems; it’s about learning from the experience to improve future responses. Post-disaster recovery encompasses a series of crucial steps designed to not only return to normal operations but also to analyze what worked, what didn’t, and how to enhance preparedness for future events. This phase is critical for minimizing future disruption and maximizing organizational resilience.
Post-disaster recovery activities involve a structured approach to restoring operations and analyzing the effectiveness of the disaster recovery plan. This process begins immediately after the initial crisis is mitigated and continues until normal operations are fully restored and improvements are implemented. A systematic approach ensures thoroughness and helps identify areas for improvement in future planning.
Post-Disaster Recovery Steps
The steps involved in post-disaster recovery are iterative and often overlap. A well-defined process ensures a smooth transition back to normal operations and minimizes long-term impact.
- System Restoration and Data Recovery: This involves bringing systems back online, verifying data integrity, and restoring applications. This step often requires close coordination with IT and other relevant departments.
- Facility Assessment and Repair: If the disaster affected physical infrastructure, assessing damage, securing the site, and initiating repairs are crucial steps. This may involve working with contractors and insurance providers.
- Employee and Stakeholder Communication: Keeping employees, customers, and other stakeholders informed throughout the recovery process is essential for maintaining trust and minimizing disruption. This includes regular updates on progress and any potential delays.
- Business Operations Resumption: Gradually restoring business operations, starting with critical functions and progressing to less critical ones, is key. This requires close monitoring and may involve adjusting processes temporarily.
- Financial Reconciliation and Claims Processing: This step involves assessing financial losses, filing insurance claims, and reviewing financial records. Accuracy and thorough documentation are crucial.
Key Performance Indicators (KPIs) for Disaster Recovery
Measuring the effectiveness of the disaster recovery plan is crucial for continuous improvement. KPIs provide objective data to assess performance across various aspects of the recovery process.
- Recovery Time Objective (RTO) Achievement: This measures the time taken to restore systems and applications to an operational state, compared to the predefined RTO.
- Recovery Point Objective (RPO) Achievement: This measures the amount of data loss incurred during the disaster, compared to the predefined RPO. A lower RPO indicates less data loss.
- System Uptime Percentage: This metric tracks the percentage of time systems were operational during and after the disaster.
- Employee Satisfaction with Communication: Surveys or feedback mechanisms can assess employee satisfaction with communication during the recovery process.
- Financial Impact of the Disaster: This includes direct and indirect costs associated with the disaster and recovery efforts.
Post-Incident Review Best Practices
A thorough post-incident review is essential for identifying areas for improvement in the disaster recovery plan. This review should be objective, fact-based, and involve representatives from various departments.
- Establish a Review Team: Assemble a cross-functional team with representatives from IT, operations, and other relevant departments.
- Gather Data and Evidence: Collect data from various sources, including logs, reports, and interviews, to build a comprehensive understanding of the event.
- Analyze the Event: Identify the root causes of the disaster, the effectiveness of the recovery plan, and areas for improvement.
- Develop Actionable Recommendations: Formulate specific, measurable, achievable, relevant, and time-bound (SMART) recommendations for improving the plan.
- Document Findings and Recommendations: Create a formal report documenting the findings, recommendations, and assigned responsibilities for implementing changes.
Documenting Lessons Learned and Incorporating into Future Plan Updates
Lessons learned should be documented systematically and incorporated into future updates of the disaster recovery plan. This ensures continuous improvement and enhances organizational resilience.
- Use a Standardized Template: Employ a consistent format for documenting lessons learned, ensuring clarity and ease of retrieval.
- Conduct Regular Plan Updates: Integrate lessons learned into regular plan updates, ensuring that the plan remains current and relevant.
- Utilize a Knowledge Management System: Centralize documentation in a readily accessible knowledge management system to facilitate knowledge sharing and collaboration.
- Track Implementation of Improvements: Monitor the implementation of recommended changes to ensure that lessons learned are effectively translated into action.
- Conduct Regular Drills and Exercises: Incorporate lessons learned into disaster recovery drills and exercises to test the effectiveness of improvements.
Ending Remarks
Developing a comprehensive disaster recovery plan is not a one-time task; it’s an ongoing process of assessment, adaptation, and improvement. Regular testing and updates are crucial to ensure the plan remains relevant and effective. By proactively addressing potential threats and establishing clear procedures, organizations can significantly reduce the impact of disasters and maintain operational resilience. Investing in a robust disaster recovery strategy is an investment in the long-term health and stability of your organization.
General Inquiries
What is the difference between RTO and RPO?
RTO (Recovery Time Objective) is the maximum acceptable downtime after a disaster. RPO (Recovery Point Objective) is the maximum acceptable data loss in case of a disaster.
How often should I test my disaster recovery plan?
The frequency of testing depends on your risk tolerance and the criticality of your systems. At a minimum, annual testing is recommended, with more frequent testing for high-risk systems.
What type of data backup is best for disaster recovery?
There’s no single “best” method. A combination of full and incremental backups is generally recommended to provide a balance between speed and storage efficiency.
What is a tabletop exercise?
A tabletop exercise is a low-cost, low-impact simulation where team members walk through the disaster recovery plan, identifying potential issues and refining procedures.


{kind=link}