
Effective disaster recovery planning is paramount for business continuity. A well-defined plan mitigates the impact of unforeseen events, ensuring minimal disruption to operations and data integrity. This checklist guides you through the essential steps, from identifying potential threats to implementing robust recovery strategies and post-disaster analysis.
This comprehensive guide addresses key aspects of disaster recovery, including Business Impact Analysis (BIA), data backup and recovery, system failover, communication protocols, and security considerations. By following these guidelines, organizations can significantly reduce downtime, protect valuable assets, and maintain operational resilience in the face of adversity.
Defining Disaster Recovery Planning
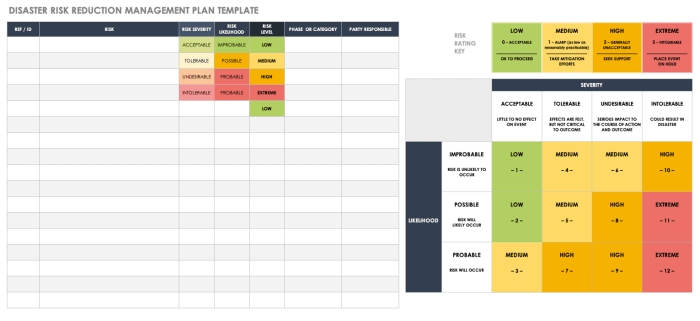
Disaster recovery planning (DRP) is the process of creating a comprehensive strategy to minimize the impact of disruptive events on an organization’s operations. This involves identifying potential threats, analyzing their likelihood and potential impact, and developing procedures to ensure business continuity in the event of a disaster. A well-defined DRP Artikels steps to restore critical systems, data, and operations to an acceptable level within a predetermined timeframe.
A robust disaster recovery plan is paramount for organizational survival and success. In today’s interconnected world, businesses face a multitude of potential threats, ranging from natural disasters like earthquakes and floods to cyberattacks and human error. Without a well-defined plan, even minor disruptions can lead to significant financial losses, reputational damage, and loss of customer trust. A strong DRP provides a framework for minimizing downtime, protecting valuable assets, and maintaining operational efficiency during and after a crisis. This ultimately safeguards the organization’s long-term viability and competitive advantage.
The Importance of a Robust Disaster Recovery Plan
A robust DRP offers several key benefits. It provides a structured approach to risk management, enabling organizations to proactively identify and mitigate potential threats. This proactive approach minimizes the likelihood of significant disruptions and reduces the potential for extensive damage. Furthermore, a well-defined plan helps streamline the recovery process, enabling faster restoration of critical systems and operations. This minimizes downtime, reducing financial losses and maintaining business continuity. A strong DRP also strengthens an organization’s resilience, building confidence among stakeholders and demonstrating a commitment to business continuity. Finally, it facilitates compliance with industry regulations and standards, which is often a legal requirement for many organizations.
Consequences of Inadequate Disaster Recovery Planning
The absence of a comprehensive DRP or a poorly executed one can have severe consequences. Financial losses can be substantial, ranging from lost revenue due to downtime to the costs of replacing damaged equipment and data. Reputational damage can also be significant, particularly if a disruption leads to customer data breaches or service outages. Loss of customer trust can be hard to recover from, potentially leading to long-term decline in market share. In addition, legal and regulatory penalties can be imposed if an organization fails to meet compliance requirements related to data protection and business continuity. Finally, inadequate planning can lead to decreased employee morale and productivity, as uncertainty and disruption can negatively impact the workforce. For example, the 2017 Equifax data breach, resulting from a failure to patch a known vulnerability, cost the company billions of dollars in fines, legal fees, and reputational damage. This highlights the significant financial and reputational risks associated with inadequate disaster recovery planning.
Identifying Potential Disasters
A comprehensive disaster recovery plan necessitates a thorough understanding of the potential threats facing your organization. Failing to identify and assess these risks leaves your business vulnerable and unprepared for disruptions that could severely impact operations and profitability. This section focuses on identifying common disaster types, analyzing their impact on various business models, and developing a robust methodology for risk assessment.
Businesses of all sizes and across all sectors face a range of potential disasters. Understanding these threats and their potential impact is crucial for effective disaster recovery planning. The vulnerabilities of different businesses vary greatly depending on their size, location, industry, and reliance on technology.
Common Disaster Types and Business Vulnerabilities
Five common disaster types that significantly impact businesses include natural disasters, technological failures, cyberattacks, human errors, and supply chain disruptions. The specific vulnerabilities of different business types to these disasters vary considerably. For instance, a small retail store in a flood-prone area is highly vulnerable to natural disasters, while a large technology firm is more susceptible to cyberattacks and technological failures.
Consider these examples: A small restaurant in a hurricane-prone coastal area faces significant risk from flooding and wind damage, potentially leading to business interruption and property loss. Conversely, a large multinational corporation with a globally distributed IT infrastructure faces a higher risk of a widespread cyberattack disrupting its operations across multiple locations. A manufacturing company relying heavily on a single supplier is vulnerable to supply chain disruptions. A hospital’s reliance on power and technology makes it vulnerable to power outages and cyberattacks. A small accounting firm faces risks related to data loss and human error. These examples highlight the diverse range of threats faced by businesses of different sizes and sectors.
Assessing the Likelihood and Impact of Potential Disasters
A structured approach is necessary to assess the likelihood and impact of potential disasters on a specific organization. This involves a combination of qualitative and quantitative analysis. A risk assessment matrix can be employed, combining the probability of occurrence with the potential severity of the impact. This allows for prioritization of risks and the allocation of resources to mitigate the most critical threats.
The assessment should consider factors such as the geographical location of the business, the type of industry, the criticality of various systems and processes, and the existing security measures in place. For instance, a business located in an earthquake-prone region should assign a higher likelihood to seismic events than a business in a geographically stable area. Similarly, a financial institution should assign a higher impact to a data breach than a retail store.
The assessment process should include the following steps:
- Identify potential disasters: Brainstorm a comprehensive list of potential disasters relevant to the organization.
- Assess likelihood: Assign a probability score (e.g., low, medium, high) to each disaster based on historical data, expert opinion, and risk analysis tools.
- Assess impact: Determine the potential impact of each disaster on business operations, financial performance, and reputation. This could be quantified using metrics such as downtime costs, data loss costs, and reputational damage.
- Calculate risk: Multiply the likelihood and impact scores to obtain a risk score for each disaster. This provides a quantitative measure of the overall risk posed by each threat.
- Prioritize risks: Focus mitigation efforts on the disasters with the highest risk scores. This ensures that resources are allocated effectively to address the most critical threats.
By using a structured approach, organizations can develop a clear understanding of the potential threats they face and prioritize their disaster recovery efforts accordingly. This allows for the development of a tailored disaster recovery plan that effectively mitigates the most significant risks.
Business Impact Analysis (BIA)
A Business Impact Analysis (BIA) is a critical component of any effective disaster recovery plan. It systematically identifies and assesses the potential consequences of disruptions to business operations, allowing organizations to prioritize recovery efforts and allocate resources effectively. By understanding the impact of various disruptions, businesses can make informed decisions about acceptable downtime and data loss, ultimately minimizing financial and reputational damage.
The process of conducting a BIA involves several key steps. First, a team representing various business units should be assembled. This team will collaborate to identify critical business functions and their dependencies. Next, the team assesses the potential impact of various disruptions—such as natural disasters, cyberattacks, or equipment failures—on each function. This assessment considers factors like financial losses, legal liabilities, and reputational damage. Finally, the team determines recovery time objectives (RTOs) and recovery point objectives (RPOs) for each critical function. RTOs define the maximum acceptable downtime, while RPOs specify the maximum acceptable data loss.
Key Metrics in a BIA
The BIA process requires the quantification of potential impacts. This necessitates the inclusion of specific, measurable metrics. These metrics provide a concrete understanding of the consequences of different disruption scenarios and inform the prioritization of recovery strategies. Using objective metrics allows for a more rigorous and defensible analysis, enabling data-driven decision-making.
Sample BIA Report
The following table presents a sample BIA report for a hypothetical e-commerce business. Note that the RTO and RPO values are illustrative and would vary depending on the specific business and its tolerance for downtime and data loss.
| Critical Business Function | Description | Potential Impact of Disruption | RTO (Hours) | RPO (Hours) |
|---|---|---|---|---|
| Order Processing | Handling customer orders from placement to fulfillment. | Loss of revenue, customer dissatisfaction, reputational damage. | 4 | 2 |
| Website Availability | Maintaining the online storefront accessible to customers. | Loss of sales, damage to brand image, potential loss of market share. | 2 | 1 |
| Inventory Management | Tracking and managing product inventory levels. | Inability to fulfill orders, potential stockouts, financial losses. | 8 | 4 |
| Customer Support | Providing assistance to customers via phone, email, or chat. | Decreased customer satisfaction, potential loss of loyalty, negative reviews. | 12 | 0 |
| Payment Processing | Securing and processing customer payments. | Inability to process transactions, financial losses, legal implications. | 1 | 0 |
Data Backup and Recovery Strategies

A robust data backup and recovery strategy is the cornerstone of any effective disaster recovery plan. Data loss can cripple an organization, halting operations and potentially leading to significant financial and reputational damage. Therefore, understanding and implementing appropriate backup and recovery methods is critical to ensuring business continuity. This section details various strategies, comparing their strengths and weaknesses to help you design a resilient system.
Effective data backup and recovery involves selecting appropriate methods, considering factors such as data volume, criticality, recovery time objectives (RTO), and recovery point objectives (RPO). These objectives define the acceptable downtime and data loss in the event of a disaster. A well-defined strategy incorporates redundancy and failover mechanisms to minimize disruption and ensure quick recovery.
Data Backup and Recovery Methods
Several methods exist for backing up and recovering data, each with its own advantages and disadvantages. The choice depends on the specific needs and resources of the organization. Common methods include full backups, incremental backups, differential backups, and continuous data protection (CDP). Full backups copy all data, while incremental backups only copy data changed since the last backup (full or incremental). Differential backups copy data changed since the last full backup. CDP provides near real-time data protection.
On-Site, Off-Site, and Cloud-Based Backup Solutions
Data backup solutions can be broadly categorized into on-site, off-site, and cloud-based options. Each approach offers different levels of protection and presents unique advantages and disadvantages.
| Backup Solution | Advantages | Disadvantages |
|---|---|---|
| On-Site | Fast access to data, relatively low cost (initial investment). | Vulnerable to on-site disasters (fire, flood, theft), limited redundancy. |
| Off-Site | Protection against on-site disasters, increased redundancy. | Slower recovery times, higher costs (storage, transportation, security). |
| Cloud-Based | High redundancy, scalability, cost-effective for large datasets, accessibility from anywhere. | Dependence on internet connectivity, potential security concerns, vendor lock-in. |
Designing a Redundant Data Backup Strategy
A truly resilient backup strategy incorporates redundancy and failover mechanisms. This ensures that data is protected against multiple failure points and that recovery can be swift and efficient. A common approach involves a 3-2-1 backup strategy.
The 3-2-1 strategy recommends maintaining three copies of your data, on two different media types, with one copy stored offsite. For example, one copy could be on a local server (on-site), another on an external hard drive (off-site), and a third in the cloud. This layered approach protects against various failure scenarios, from hardware malfunctions to natural disasters.
Failover mechanisms, such as redundant servers or geographically dispersed data centers, ensure continuous operation even if a primary system fails. These mechanisms automatically switch to a backup system, minimizing downtime.
System Recovery and Failover
System recovery and failover are critical components of a robust disaster recovery plan. Failover ensures business continuity by quickly switching operations to a secondary system in the event of a primary system failure, minimizing downtime and data loss. A well-defined recovery strategy, including detailed failover procedures, is essential for a swift and effective response to disasters.
System failover is the process of transferring operational functions from a primary system to a secondary system in the event of a failure or disruption. Its importance lies in maintaining business operations and minimizing the impact of unforeseen events. A successful failover ensures that critical applications and data remain accessible, preventing significant financial losses and reputational damage. The speed and efficiency of the failover process directly correlate with the overall resilience of the organization.
Implementing a System Failover Mechanism
Implementing a system failover mechanism involves several key steps, from planning and design to testing and maintenance. Careful consideration must be given to the specific needs and vulnerabilities of the organization’s systems.
- Identify Critical Systems: Determine which systems are essential for business operations and require failover protection. This prioritization guides resource allocation and ensures the most critical systems are protected first.
- Choose a Failover Strategy: Select an appropriate failover strategy, such as active-passive, active-active, or geographic redundancy, based on the organization’s risk tolerance and recovery time objectives (RTOs).
- Design and Implement the Failover Infrastructure: This involves setting up the necessary hardware and software, including redundant servers, network infrastructure, and storage. Configuration must be precise and tested thoroughly.
- Develop Failover Procedures: Create detailed, step-by-step procedures for initiating and managing the failover process. These procedures should be clearly documented and readily accessible to the IT team.
- Test the Failover System: Regularly test the failover system to ensure its functionality and identify any weaknesses. Testing should simulate real-world scenarios to validate the effectiveness of the plan.
- Monitor and Maintain the System: Continuous monitoring of the failover system is crucial to identify potential problems and ensure its readiness. Regular maintenance is essential to prevent unexpected failures.
Restoring Critical Systems After a Disaster
A structured approach is crucial for restoring critical systems after a disaster. This involves a coordinated effort to assess damage, prioritize recovery efforts, and implement the failover procedures. The following table Artikels a step-by-step guide.
| Step | Action | Responsibility | Time Estimate |
|---|---|---|---|
| 1 | Assess the damage and identify affected systems. | IT Team, Disaster Recovery Team | 30 minutes – 2 hours |
| 2 | Activate the disaster recovery plan. | Disaster Recovery Manager | 15 minutes |
| 3 | Initiate failover to secondary systems. | IT Team | 30 minutes – 4 hours (depending on complexity) |
| 4 | Verify system functionality and data integrity. | IT Team | 1-2 hours |
| 5 | Restore data from backups. | IT Team | Variable, depending on data size and backup strategy |
| 6 | Resume critical business operations. | All relevant teams | Variable, depending on system complexity and data recovery |
| 7 | Conduct a post-incident review. | Disaster Recovery Team | 1-2 days |
Communication and Coordination Plan
Effective communication is the backbone of a successful disaster recovery. A well-defined communication plan ensures that all stakeholders are informed and coordinated during and after a disruptive event, minimizing downtime and facilitating a swift recovery. This section details the creation of a comprehensive communication strategy, encompassing notification procedures, a clear communication hierarchy, and contingency plans for communication disruptions.
A robust communication plan requires proactive preparation and clear articulation of roles and responsibilities. It should Artikel procedures for various scenarios, from minor outages to large-scale disasters. The plan should also detail how communication will be maintained even when primary channels are unavailable.
Communication Plan Procedures
The communication plan should detail specific steps for notifying stakeholders during a disaster. This includes defining who needs to be notified (e.g., employees, clients, vendors, regulatory bodies), the order of notification, and the preferred methods of contact (e.g., email, SMS, phone calls, public announcements). The plan should also specify the information to be conveyed in each notification, ensuring clarity and consistency across all communications. For example, a company might use a tiered system, notifying key personnel first with a general overview, followed by broader communications with more specific details as they become available. Regular testing and drills will ensure the plan’s effectiveness.
Communication Tree and Reporting Structure
A visual communication tree, often depicted as an organizational chart, clearly illustrates the chain of command and reporting structure during a disaster. This chart defines who is responsible for communicating with whom, ensuring efficient information flow and accountability. For example, the CEO might be at the top, delegating communication responsibilities to department heads, who in turn communicate with their teams. This hierarchical structure helps prevent confusion and ensures that critical information reaches the appropriate individuals promptly. The tree should also indicate alternate communication paths in case primary contacts are unavailable.
Maintaining Communication During Disruptions
Disasters often disrupt standard communication channels. Therefore, the communication plan must include contingency plans for maintaining communication when primary methods fail. This might involve utilizing backup communication systems, such as satellite phones, two-way radios, or alternative internet connections. Pre-arranged meeting points or designated communication hubs can also be established as physical alternatives. Furthermore, the plan should include procedures for disseminating information through alternative channels, such as social media or public broadcast systems, in situations where widespread communication is necessary. Regular testing of these backup systems is crucial to ensure their readiness and functionality.
Testing and Maintenance
A robust disaster recovery plan is only as good as its implementation. Regular testing is crucial to ensure the plan’s effectiveness and identify any weaknesses or gaps before a real disaster strikes. This proactive approach minimizes disruption and maximizes the chances of a successful recovery. Without regular testing, the plan becomes outdated and unreliable, potentially leading to significant losses during a real emergency.
Testing allows for the identification of flaws in the plan, such as insufficient resources, unclear procedures, or outdated contact information. It also provides valuable training for personnel involved in the recovery process, improving their preparedness and response capabilities. Furthermore, testing provides an opportunity to refine and improve the plan based on the lessons learned during the exercises.
Disaster Recovery Plan Testing Methodologies
Several methodologies exist for testing a disaster recovery plan, each offering different levels of complexity and realism. The choice of methodology depends on factors such as budget, available resources, and the criticality of the systems being tested.
- Tabletop Exercises: These are low-cost, low-impact exercises involving a walkthrough of the disaster recovery plan with key personnel. Participants discuss how they would respond to various disaster scenarios, identifying potential problems and areas for improvement. Tabletop exercises are useful for identifying procedural gaps and communication issues. For example, a tabletop exercise might simulate a power outage and walk through the steps to restore critical systems using backup generators and redundant systems. The exercise would reveal any communication bottlenecks between IT and other departments.
- Functional Exercises: These exercises involve testing specific components of the disaster recovery plan, such as data backup and restoration or system failover. This is a more hands-on approach than a tabletop exercise, offering a more realistic test of individual components, although not the full plan. For instance, a functional exercise might focus solely on restoring a database from a backup, assessing the restoration time and data integrity.
- Full-Scale Drills: These are the most comprehensive and realistic type of testing. They involve simulating a real-world disaster and activating the entire disaster recovery plan. This type of test typically involves relocating to a secondary site and fully operating from that location. A full-scale drill could involve simulating a major fire and relocating all critical operations to a secondary data center, testing the entire recovery process from start to finish. This method is expensive and resource-intensive but provides the most comprehensive evaluation.
Disaster Recovery Plan Testing and Maintenance Schedule
A regular schedule for testing and maintenance is vital to ensure the plan remains current and effective. The frequency of testing should be determined based on the criticality of the systems and the potential impact of a disaster. A sample schedule could include:
- Annual Full-Scale Drill: A complete simulation of a disaster scenario, testing the entire recovery process.
- Semi-Annual Functional Exercises: Testing specific components of the plan, such as data backup and restoration or system failover.
- Quarterly Tabletop Exercises: Walkthroughs of the plan with key personnel to identify potential issues and refine procedures.
- Monthly Plan Review: A review of the plan to ensure accuracy and identify any updates needed. This could include checking contact information, updating system configurations, and reviewing recent changes to the IT infrastructure.
Recovery Site Selection and Setup

Selecting and setting up a recovery site is a critical component of any robust disaster recovery plan. The choice of site directly impacts the speed and efficiency of your organization’s recovery following a disruptive event. Careful consideration of several factors is essential to ensure business continuity.
Factors influencing recovery site selection include proximity to the primary site (minimizing recovery time), connectivity (reliable network access for data replication and remote access), availability (ensuring the site is readily available when needed), cost (considering lease or purchase costs, infrastructure requirements, and ongoing maintenance), security (physical and cyber security measures to protect sensitive data), capacity (sufficient space and resources to accommodate your organization’s needs), and compliance (adherence to relevant regulations and standards). The ideal site will offer a balance between these factors, prioritizing those most critical to your business operations.
Recovery Site Types: Hot, Warm, and Cold Sites
Different types of recovery sites cater to varying recovery time objective (RTO) and recovery point objective (RPO) requirements. A hot site offers immediate recovery capabilities, with fully configured hardware, software, and data mirroring. A warm site provides partially configured systems, requiring some setup and data restoration post-disaster. A cold site offers only basic infrastructure, needing significant setup and data restoration before becoming operational. The choice depends on the organization’s tolerance for downtime and budget constraints. For instance, a financial institution with stringent regulatory compliance might opt for a hot site, while a smaller business with a lower tolerance for downtime might choose a warm site. A cold site would be suitable for businesses with a longer RTO and lower RPO.
Hot Site Setup and Configuration
A hot site involves replicating your entire IT infrastructure, including servers, network equipment, and applications, at a secondary location. Real-time data replication ensures that the hot site mirrors the primary site’s data at all times. Regular testing and maintenance are crucial to ensure the site remains fully operational and ready to take over seamlessly in the event of a disaster. This often involves regular failover drills and verification of network connectivity and data synchronization. The setup includes establishing robust security measures, redundant power supplies, and environmental controls to maintain optimal operating conditions.
Warm Site Setup and Configuration
Warm sites offer a balance between cost and recovery time. Essential hardware and software are pre-configured, but data replication might not be real-time. The setup typically involves pre-installed servers and network equipment, but data restoration from backups will be required following a disaster. Configuration includes establishing network connectivity, installing necessary software, and restoring data from backups. This requires a detailed plan outlining the data restoration process, including priorities and dependencies. Regular testing and maintenance ensure the site’s readiness, focusing on verifying the speed and efficiency of data restoration.
Cold Site Setup and Configuration
Cold sites provide the most basic infrastructure – essentially, just space and power. Hardware, software, and data must be acquired and installed post-disaster. The setup involves procuring necessary hardware and software, establishing network connectivity, and restoring data from offsite backups. This process can be time-consuming, making it suitable for organizations with longer recovery time objectives. A detailed plan is essential, outlining the procurement process, installation procedures, and data restoration strategies. Testing involves simulating the setup and data restoration process to identify and address potential bottlenecks.
Security Considerations
Disaster recovery planning must incorporate robust security measures to protect sensitive data and systems throughout the entire recovery process. Neglecting security can lead to significant financial losses, reputational damage, and legal repercussions. A comprehensive approach ensures business continuity while maintaining the confidentiality, integrity, and availability of critical information.
Protecting data and systems during and after a disaster requires a multi-layered security strategy. This involves anticipating potential threats, implementing preventative measures, and establishing procedures for responding to security incidents that may arise during the recovery phase. A well-defined security plan minimizes vulnerabilities and ensures a swift and secure return to normal operations.
Potential Security Threats During and After a Disaster
A range of security threats can emerge during and after a disaster. These threats can be internal, such as accidental data deletion by personnel during the recovery process, or external, such as malicious actors exploiting vulnerabilities in temporarily weakened security systems. Physical security breaches at recovery sites are also a significant concern. For instance, a flood might damage physical security measures, leaving equipment vulnerable to theft or unauthorized access. Furthermore, the disruption of normal network operations could increase the risk of phishing attacks targeting employees attempting to access critical systems remotely.
Security Measures During Recovery
Implementing strong security measures is crucial during the recovery process. This includes access control measures restricting access to systems and data based on the principle of least privilege. Multi-factor authentication should be mandatory for all personnel accessing recovery systems. Regular security audits and penetration testing of recovery systems are essential to identify and address vulnerabilities proactively. Encryption of all data, both in transit and at rest, is vital for protecting sensitive information. Finally, robust intrusion detection and prevention systems should be in place to monitor network traffic and respond to suspicious activity. For example, implementing a security information and event management (SIEM) system can help monitor and analyze security logs from various sources, enabling faster identification and response to security incidents.
Maintaining Data Integrity and Confidentiality
Maintaining data integrity and confidentiality throughout the recovery process requires rigorous attention to detail. This involves implementing strict data backup and recovery procedures, including regular verification of data integrity through checksums or similar methods. Access control lists should be meticulously managed to ensure that only authorized personnel can access sensitive data. The use of strong encryption algorithms is essential to protect data confidentiality, both during transmission and storage. Regular security awareness training for all personnel involved in the recovery process is also critical to minimize human error and reduce the risk of insider threats. A robust incident response plan should be in place to address any security breaches that might occur during the recovery process, ensuring a swift and effective response to minimize damage and maintain data integrity. For example, a company might use blockchain technology to ensure the immutability of critical records during the recovery phase, adding another layer of security and trust.
Post-Disaster Recovery and Lessons Learned

Effective post-disaster recovery is crucial not only for resuming business operations but also for improving future disaster preparedness. A well-defined recovery process minimizes downtime, reduces financial losses, and safeguards valuable data and systems. Learning from past events is paramount to continuous improvement in disaster recovery planning.
Post-disaster recovery involves a systematic approach to restoring operations to normalcy. This process goes beyond simply restoring systems; it encompasses assessing the damage, prioritizing recovery efforts, and ensuring the safety and well-being of employees. A thorough analysis of the event itself is vital for identifying weaknesses in the existing plan and areas for improvement.
Post-Disaster Recovery Steps
The initial phase focuses on stabilizing the situation, ensuring the safety of personnel, and securing the affected facilities. This involves conducting a thorough damage assessment, activating the communication plan to reach employees and stakeholders, and establishing temporary operational capabilities. Subsequent steps include restoring critical systems and data, conducting a comprehensive review of the disaster’s impact, and resuming normal business operations. Finally, a full assessment of the recovery process should be undertaken to identify areas for improvement.
Documenting Lessons Learned
A structured approach to documenting lessons learned is essential. This can be achieved through a post-incident review meeting where team members share their experiences and insights. A formal report should be compiled, outlining the events leading to the disaster, the effectiveness of the disaster recovery plan, areas where the plan fell short, and specific recommendations for improvements. This report should be distributed to all relevant stakeholders and used to update the disaster recovery plan. For example, if communication breakdowns were identified, the report might recommend implementing a more robust communication system or providing additional training to staff. If data backup procedures proved insufficient, the report might suggest adopting a more frequent backup schedule or utilizing a different backup method.
Best Practices for Continuous Improvement
Regularly reviewing and updating the disaster recovery plan is critical. This should include incorporating lessons learned from past incidents, adjusting the plan to reflect changes in the business environment, and conducting regular testing and drills. For instance, incorporating new technologies into the recovery plan, conducting table-top exercises to test the plan’s effectiveness, and updating contact information for key personnel are all vital components of continuous improvement. Furthermore, conducting periodic reviews of the Business Impact Analysis (BIA) ensures the plan remains relevant and addresses current business priorities. By actively engaging in these processes, organizations can significantly improve their resilience and preparedness against future disasters.
Final Review

Implementing a robust disaster recovery plan is not merely a reactive measure; it’s a proactive investment in the long-term health and stability of your organization. By diligently following this checklist and regularly testing your plan, you can significantly reduce the risk of catastrophic losses and maintain business continuity even during unexpected crises. Remember that continuous improvement and adaptation are key to maintaining a truly effective plan.
Commonly Asked Questions
What is the difference between RTO and RPO?
RTO (Recovery Time Objective) is the maximum acceptable downtime after a disaster. RPO (Recovery Point Objective) is the maximum acceptable data loss in case of a disaster.
How often should I test my disaster recovery plan?
The frequency of testing depends on your risk tolerance and the criticality of your systems. At minimum, annual testing is recommended, with more frequent testing for high-risk systems.
What is a “cold site” in disaster recovery?
A cold site is a basic facility with power and connectivity, requiring significant time and effort to become operational after a disaster. It offers the lowest cost but longest recovery time.
What are some common security threats during disaster recovery?
Common threats include unauthorized access to backup data, malware infection of recovery systems, and data breaches during the restoration process.


{kind=link}